Text size
Line height
Text spacing
In today’s data-driven world, immense streams of information are generated every second. This course is designed to equip you with the essential concepts, tools, and architectures needed to capture, store, and analyze massive datasets. Whether you are looking to enhance your current technical skills or dive into the world of data engineering, you will gain practical insights into how modern organizations turn raw data into actionable intelligence.
This intermediate-level academic micro-credential programme offers comprehensive knowledge of big data technologies, including distributed processing, scalable platforms, data analytics, and real-world applications. It is meticulously designed to equip learners with the ability to design, evaluate, and apply robust big data solutions within digital intelligence environment.
Programme Structure: Earn as You Learn!
This macro-certificate is broken down into 3 specialized Micro-certificates and a total of 11 stackable Digital Badges. Completing the modules earns you digital badges, which stack up into micro-certificates, ultimately culminating in your full Macro-Certificate.
1. Micro-certificate 1: Foundations of Scalable Big Data Systems and Distributed Intelligence
Focuses on the core architecture and fundamental processing mechanics of large-scale data.
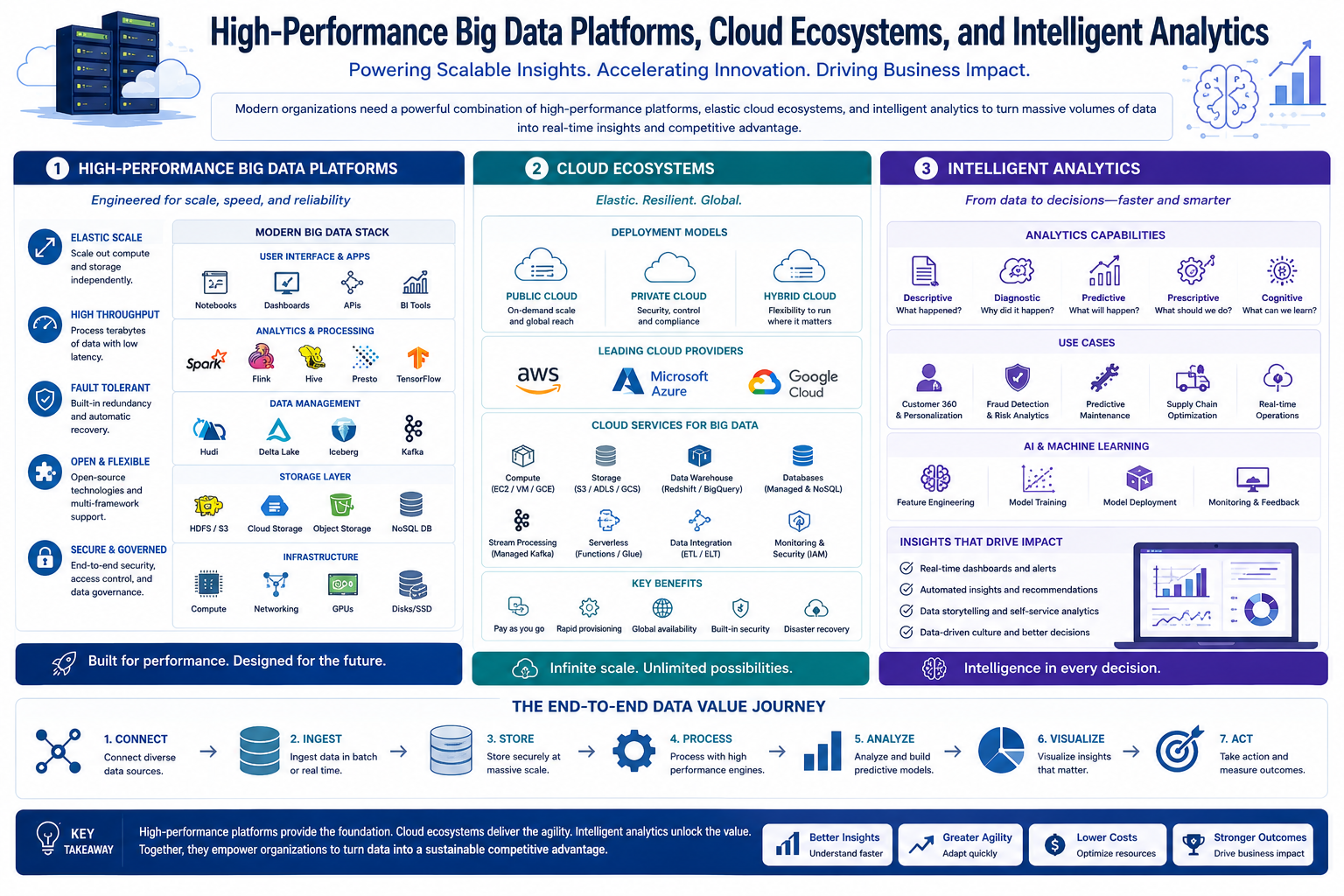
2. Micro-certificate 2: High-Performance Big Data Platforms, Cloud Ecosystems, and Intelligent Analytics
Focuses on high-performance frameworks, modern cloud infrastructure, and turning data into actionable insights.
3. Micro-certificate 3: Data-Driven Applications, Digital Economy Systems, and Cybersecurity
Focuses on industry-specific domain applications and critical data protection.
The course balances 30 hours of guided virtual engagement (short lecture videos, podcast videos, live demo simulations, and synchronous breakout room discussions) with 90 hours of self-paced learning (hands-on lab work, case study reports, and mini-project development).
Assessments are completely coursework-based and practical ranging from interactive quizzes and visualization assignments to real-world architectural design tasks ensuring you build a portfolio ready for the digital industry!
 |
This micro-credential provides a comprehensive, intermediate-level foundation in big data. It progresses from core conceptual definitions and applications to hands-on infrastructure management (Hadoop & NoSQL). Students then advance to batch processing techniques (via MapReduce programming) and wrap up with live data streams and real-time technology using Apache Storm. |
Big Data is defined by its massive Volume, high Velocity, and diverse Variety, representing an ocean of information that traditional software simply cannot handle. To make sense of this chaos, Big Data Computing utilizes distributed frameworks like Hadoop and Apache Spark, which break tasks into smaller chunks and process them across clusters of servers simultaneously. This computational power transforms raw data into Applications that define modern life, from Healthcare systems that predict disease outbreaks to Retail algorithms that personalize shopping experiences and Finance tools that detect fraud in real-time. Ultimately, Big Data is the engine of the 21st century, turning digital noise into the actionable insights that power smart cities and global economies.
The infographics describe in detail the foundation layers of big data. Also, it shows the key enablers and tools associated with big data.
The slides describe the core components and processes involved in big data management and modelling. It outlines the Hadoop architecture, highlighting how systems like HDFS and YARN handle distributed storage and resource scheduling. The visual further breaks down data processing services that utilize programming frameworks such as MapReduce, Apache Spark, and Flink for high-speed analysis. Additionally, it compares query-based processing tools like Hive and Presto, which facilitate efficient data retrieval through SQL-like languages.
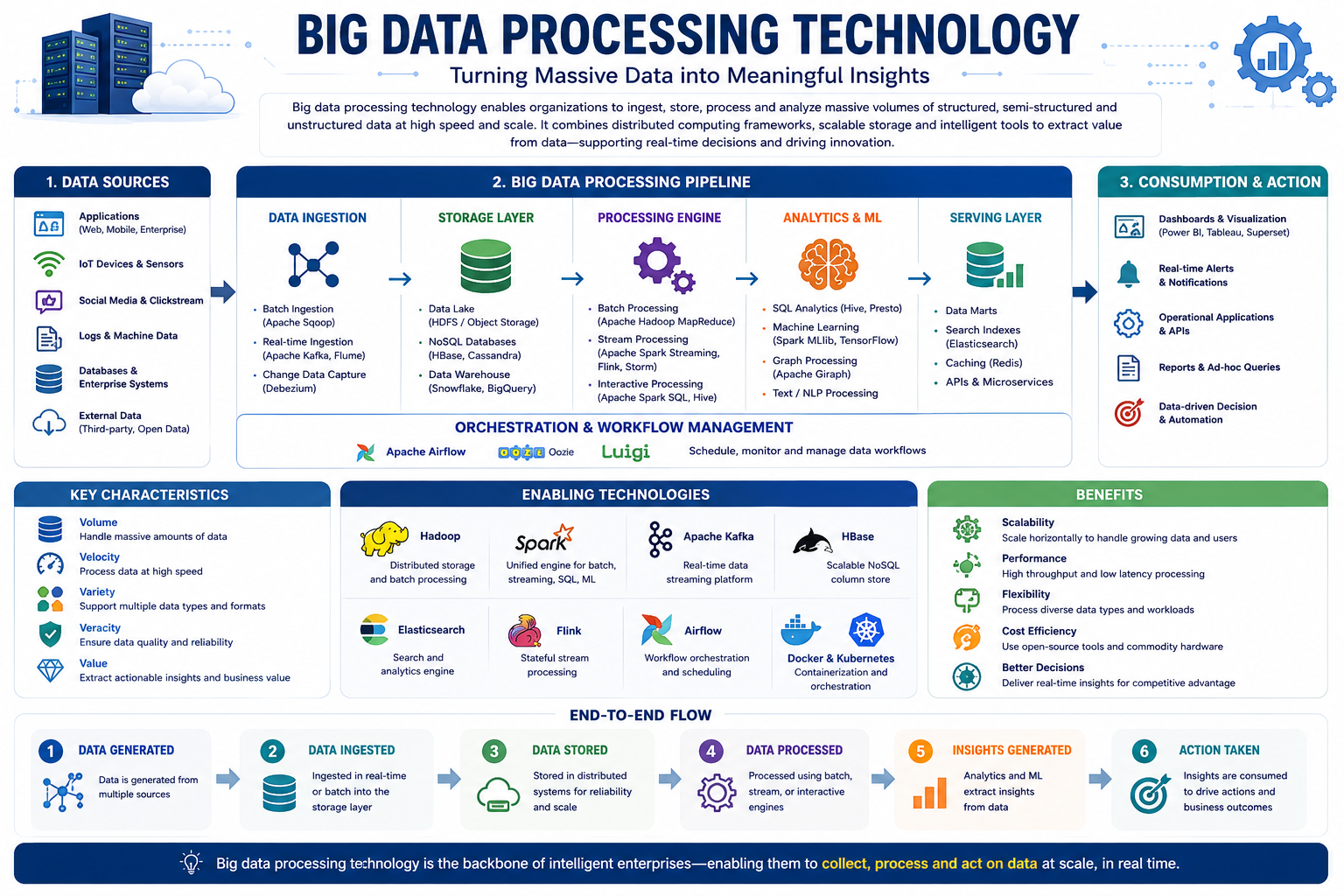
The slides outline the five essential stages required for efficient big data processing, beginning with the extraction and validation of information from various sources. It details how data is transformed into usable formats and loaded into centralized systems before being analyzed through visualization and business intelligence tools. The final phase emphasizes the role of machine learning, explaining how supervised, unsupervised, and reinforcement learning help automate pattern recognition and predictive modeling.
The provided video explores the essential structure and logic behind the MapReduce architectural model. It outlines the fundamental principles that govern how the system processes large-scale data across distributed networks. By examining the individual components that make up the framework, the text illustrates how hardware and software work in tandem. Additionally, the source addresses the programming methodologies required to implement and manage these complex data tasks. Overall, the documentation serves as a comprehensive guide to understanding the internal mechanics of this data processing technology.
The provided text outlines the core structural and operational elements of the MapReduce architecture. It highlights the fundamental conceptual theories that underpin this specific data processing model. Additionally, the source identifies the physical components required to build and maintain the system's infrastructure. It also addresses the software development side by focusing on the specialized programming techniques used within the framework.
The slides is continuing the first part slides. Overall, these excerpts serve as a foundational guide for understanding how the technology organizes and executes large-scale tasks. Through these three focus areas, the material offers a comprehensive look at the mechanics of distributed computing.
 |
Real-time data processing in big data refers to the continuous ingestion, analysis, and streaming of data as it is generated. Unlike traditional batch processing, which collects and processes large volumes of data at scheduled intervals, real-time processing operates on data almost instantly often within milliseconds or seconds. |
The slides explore the fundamental principles and practical applications of real-time big data processing, a method that prioritizes instantaneous data analysis over traditional delayed batching. By utilizing advanced frameworks like the Lambda or Kappa architectures, organizations can ingest and evaluate continuous information streams to achieve operational agility.
This text explores the fundamental principles and technical frameworks behind real-time data processing, focusing on systems that analyze information instantly as it is generated. It highlights the transition from traditional batch processing to continuous data streaming, emphasizing the need for low latency and scalability in modern digital environments.
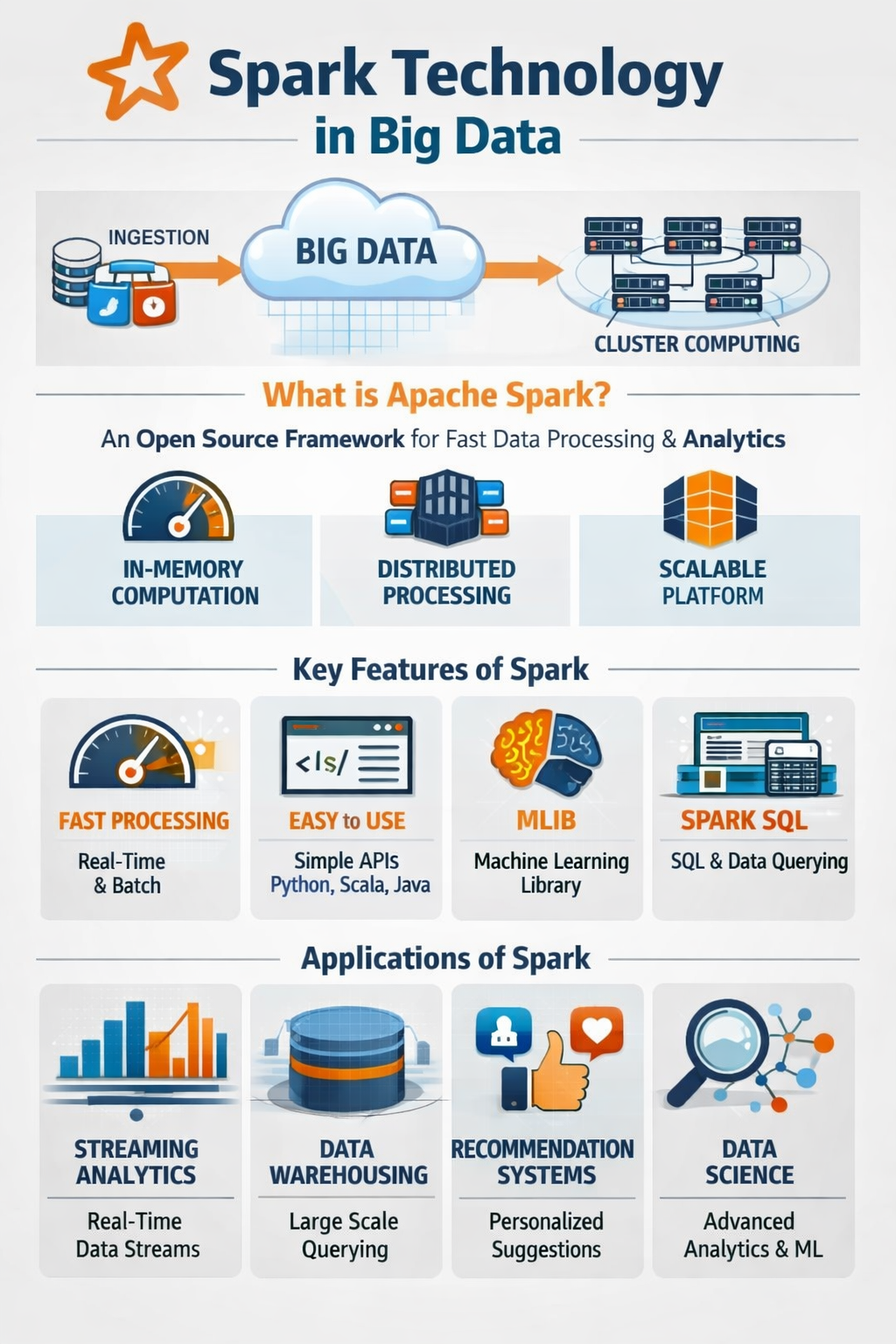
Apache Spark is an open-source, distributed data processing engine designed to handle massive datasets with incredible speed.
If big data is a mountain of raw materials, Spark is the high-speed factory that processes it into finished goods. It is currently the industry standard for big data analytics, machine learning, and real-time data processing.
The provided text offers a comprehensive technical summary of Apache Spark, an open-source framework designed for high-speed distributed computing. It highlights how the platform utilizes in-memory processing and parallel execution to overcome the performance limitations found in traditional disk-based systems.
Apache Spark is a robust open-source framework engineered to facilitate large-scale data processing through a distributed computing model. By utilizing in-memory computation, the system achieves significantly faster speeds than traditional disk-based methods, making it ideal for real-time analytics and complex machine learning tasks. The platform’s architecture relies on a driver program and executor nodes to manage tasks across vast clusters, ensuring both scalability and fault tolerance. Its diverse ecosystem includes specialized components for SQL queries, stream processing, and graph analysis, supporting multiple programming languages like Python and Scala.

Cloud-Based Big Data Management Technology is the practice of storing, cleaning, organizing, and analyzing massive datasets using remote servers hosted on the internet, rather than using physical, on-premise servers located inside a company's own data center.
The provided video outlines five distinct paradigms of computational architecture, detailing how each handles data processing and storage. Cloud computing serves as a centralized hub for scalable, remote resources, while edge and fog computing decentralize this power by moving tasks closer to the data source to minimize delay. In contrast, High-Performance Computing (HPC) utilizes massive clusters of traditional hardware to solve labor-intensive mathematical problems through brute-force parallel processing. The most radical shift is quantum computing, which leverages the unique principles of subatomic physics to perform calculations that are impossible for standard computers.
Here we explore the essential role of Big Data Visualization in converting overwhelming, high-speed datasets into actionable graphical formats. It emphasizes that traditional charting methods must be replaced by advanced techniques like heatmaps, treemaps, and data binning to prevent visual clutter and system crashes. The source highlights the importance of interactive design, allowing users to start with a broad summary before drilling down into specific details.
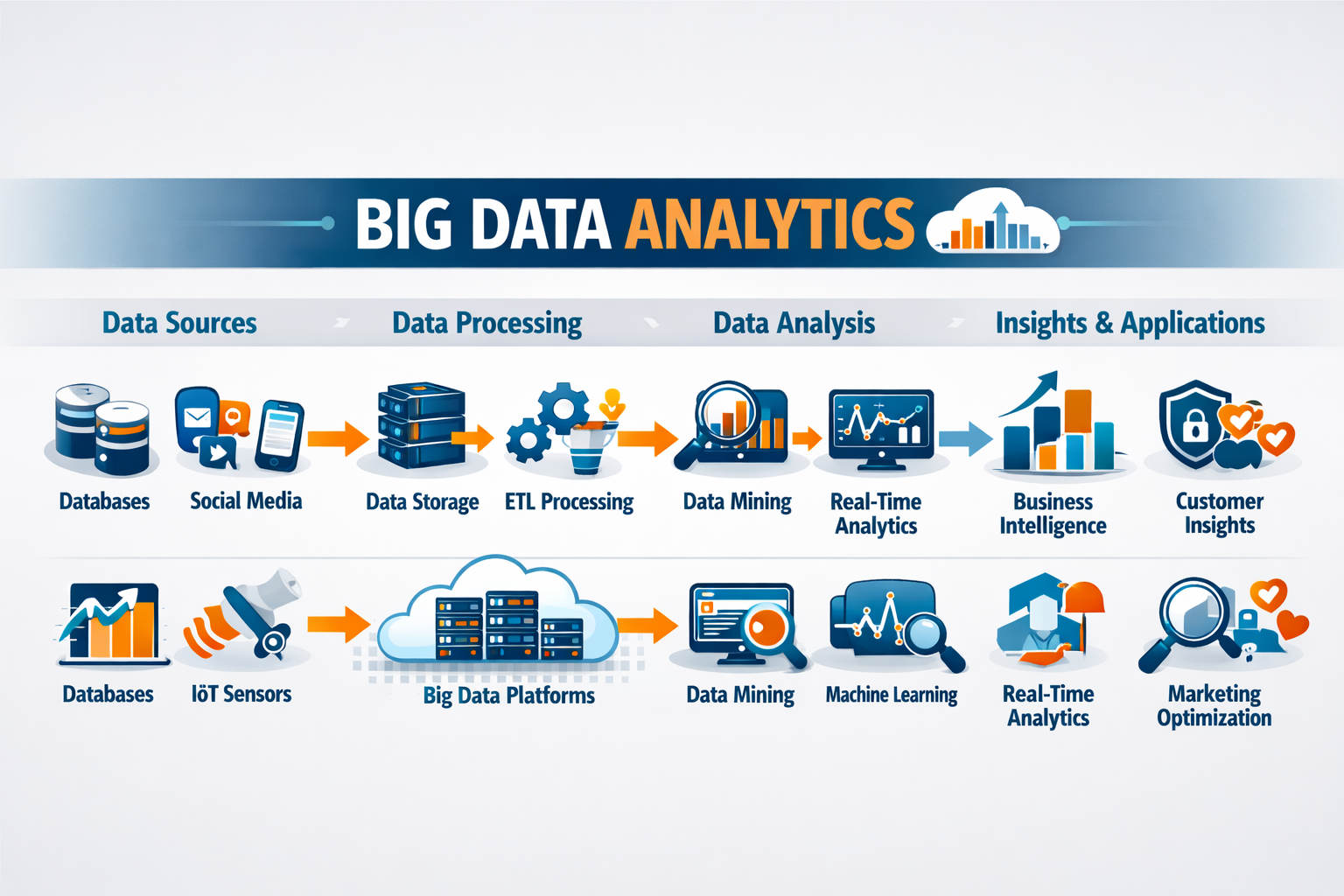
Big Data Analytics is the complex process of examining massive, fast-moving, and varied datasets to uncover hidden patterns, correlations, market trends, and customer preferences.
Essentially, it is the science of turning raw, overwhelming "noise" into actionable intelligence that organizations can use to make better, faster business decisions.
This video provides a comprehensive overview of Big Data Analytics, detailing how organizations transform massive volumes of complex information into actionable intelligence.
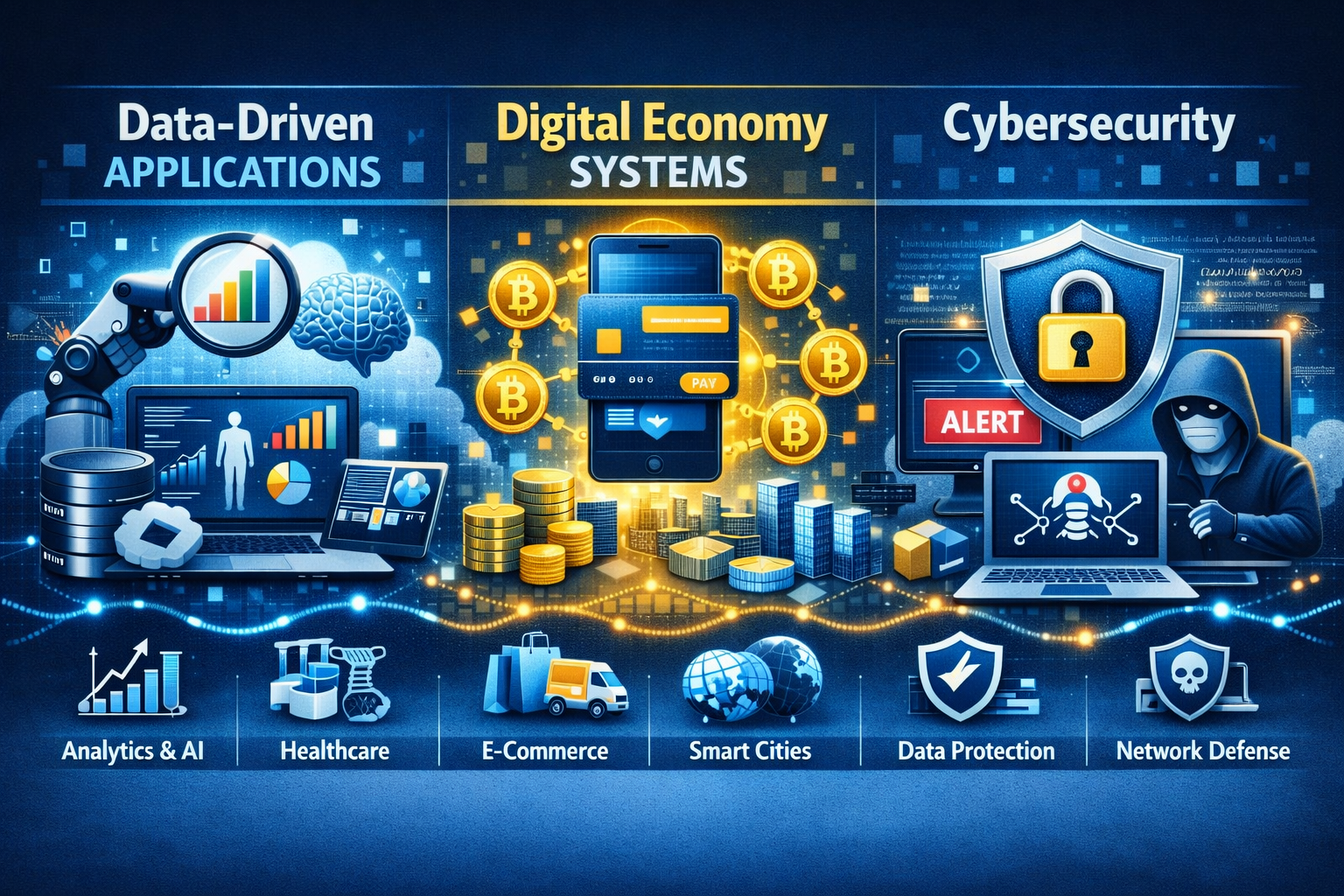
This section focuses on building things with that data (Applications), understanding the broader marketplace where it operates (Digital Economy), and defending it all from attacks (Cybersecurity).
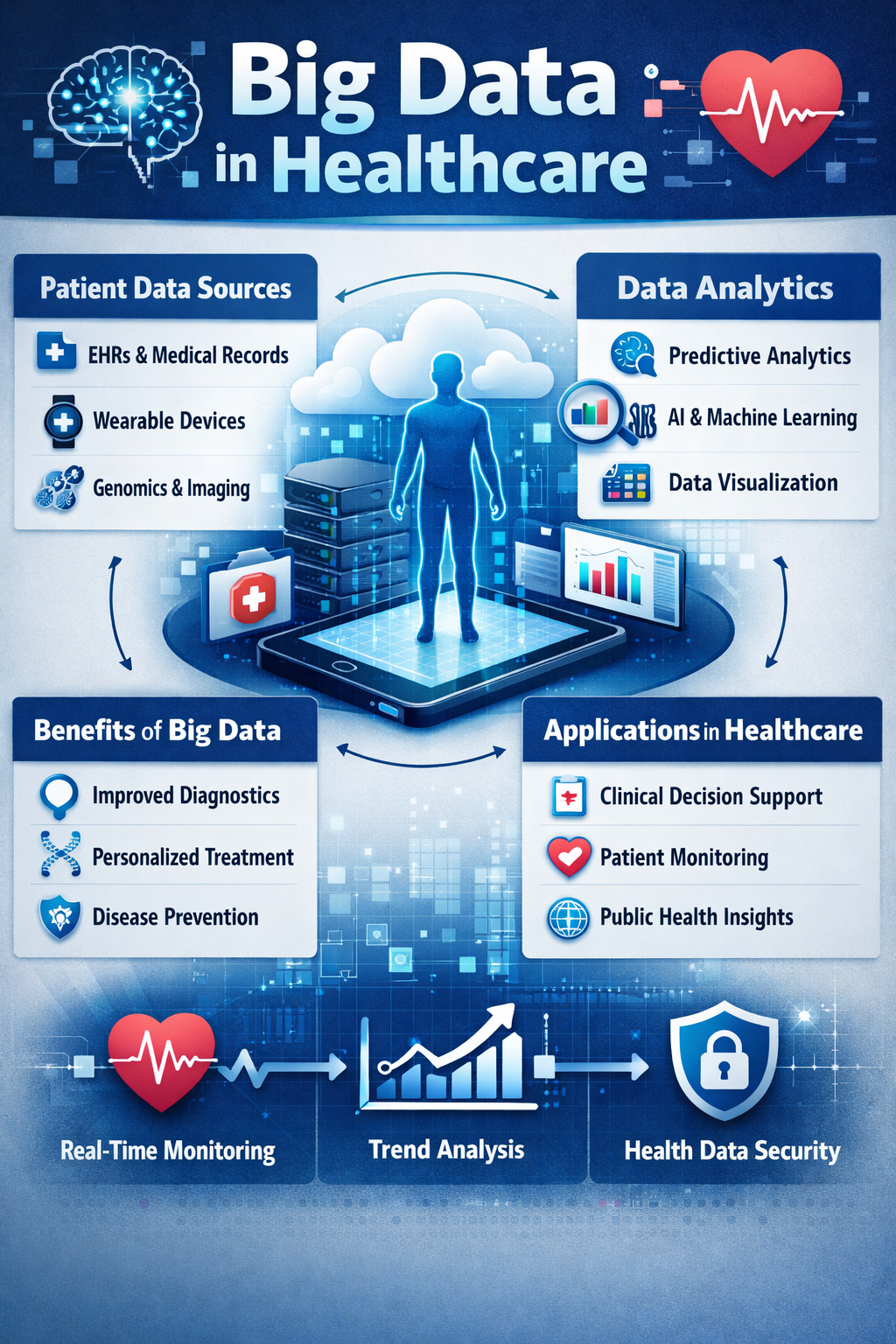
Big Data in Healthcare refers to the massive volume of health-related information collected from various sources such as electronic health records (EHRs), medical imaging, genomic data, wearable devices, and patient feedback that can be analyzed computationally to reveal patterns, trends, and associations, especially relating to human health and disease.
Modern healthcare is being transformed by Big Data, which involves managing massive and complex sets of medical information through the lenses of volume, velocity, variety, and veracity. To process this information, institutions utilize advanced tools like cloud computing, artificial intelligence, and interoperability standards to bridge the gap between different software systems.

Modern financial institutions leverage Big Data and machine learning to transform traditional banking into a high-speed, intelligent ecosystem. By processing diverse information from market feeds and consumer behavior, organizations can detect fraudulent activities and manage complex financial risks in real time.
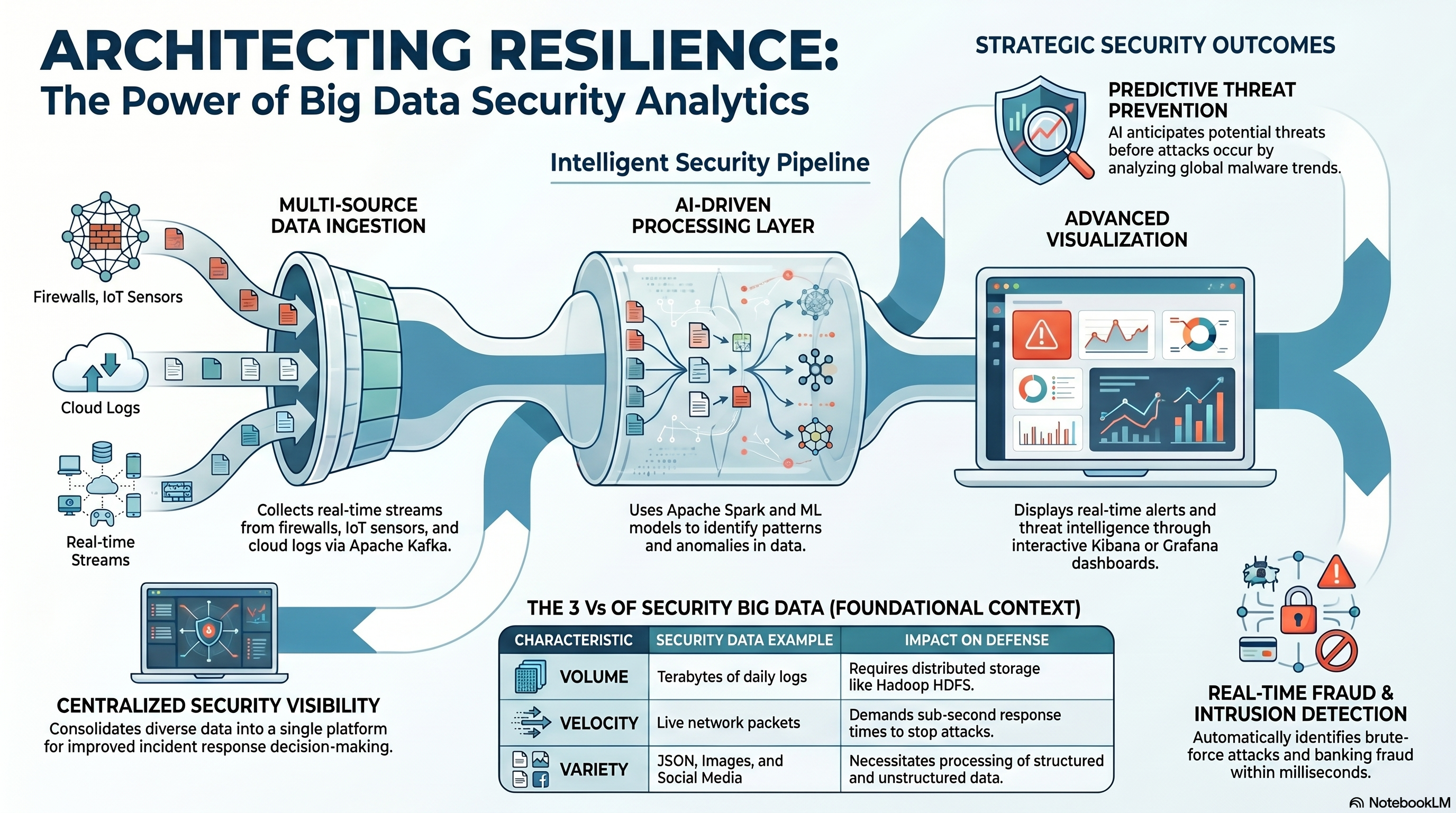
This section provides the knowledge about the integration of big data analytics and artificial intelligence within the modern cybersecurity landscape to combat sophisticated digital threats. These technologies allow organizations to process massive datasets from diverse sources, enabling real-time monitoring, anomaly detection, and automated incident responses.
