Text size
Line height
Text spacing
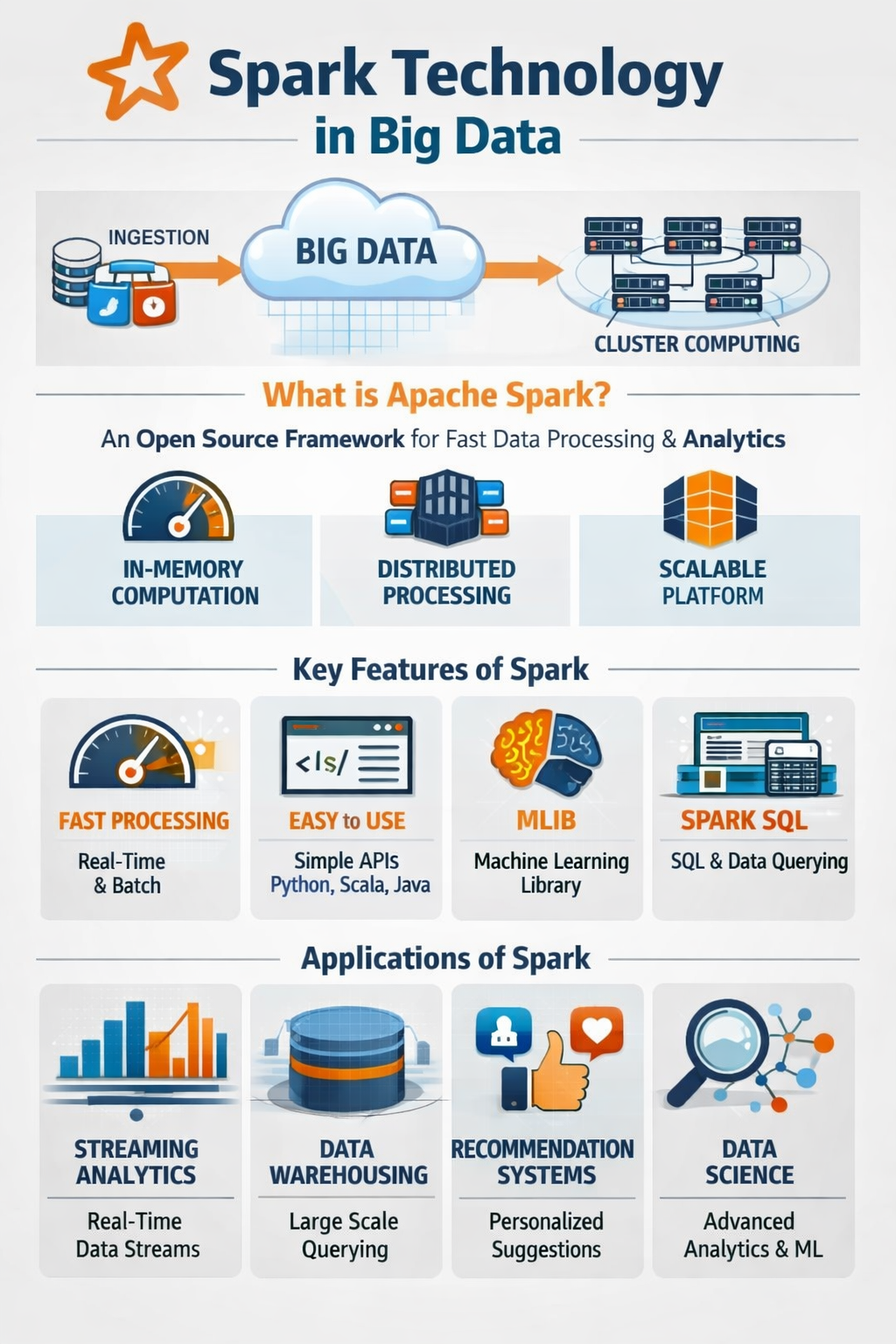
Apache Spark is an open-source, distributed data processing engine designed to handle massive datasets with incredible speed.
If big data is a mountain of raw materials, Spark is the high-speed factory that processes it into finished goods. It is currently the industry standard for big data analytics, machine learning, and real-time data processing.
The provided text offers a comprehensive technical summary of Apache Spark, an open-source framework designed for high-speed distributed computing. It highlights how the platform utilizes in-memory processing and parallel execution to overcome the performance limitations found in traditional disk-based systems.
Apache Spark is a robust open-source framework engineered to facilitate large-scale data processing through a distributed computing model. By utilizing in-memory computation, the system achieves significantly faster speeds than traditional disk-based methods, making it ideal for real-time analytics and complex machine learning tasks. The platform’s architecture relies on a driver program and executor nodes to manage tasks across vast clusters, ensuring both scalability and fault tolerance. Its diverse ecosystem includes specialized components for SQL queries, stream processing, and graph analysis, supporting multiple programming languages like Python and Scala.
