Text size
Line height
Text spacing
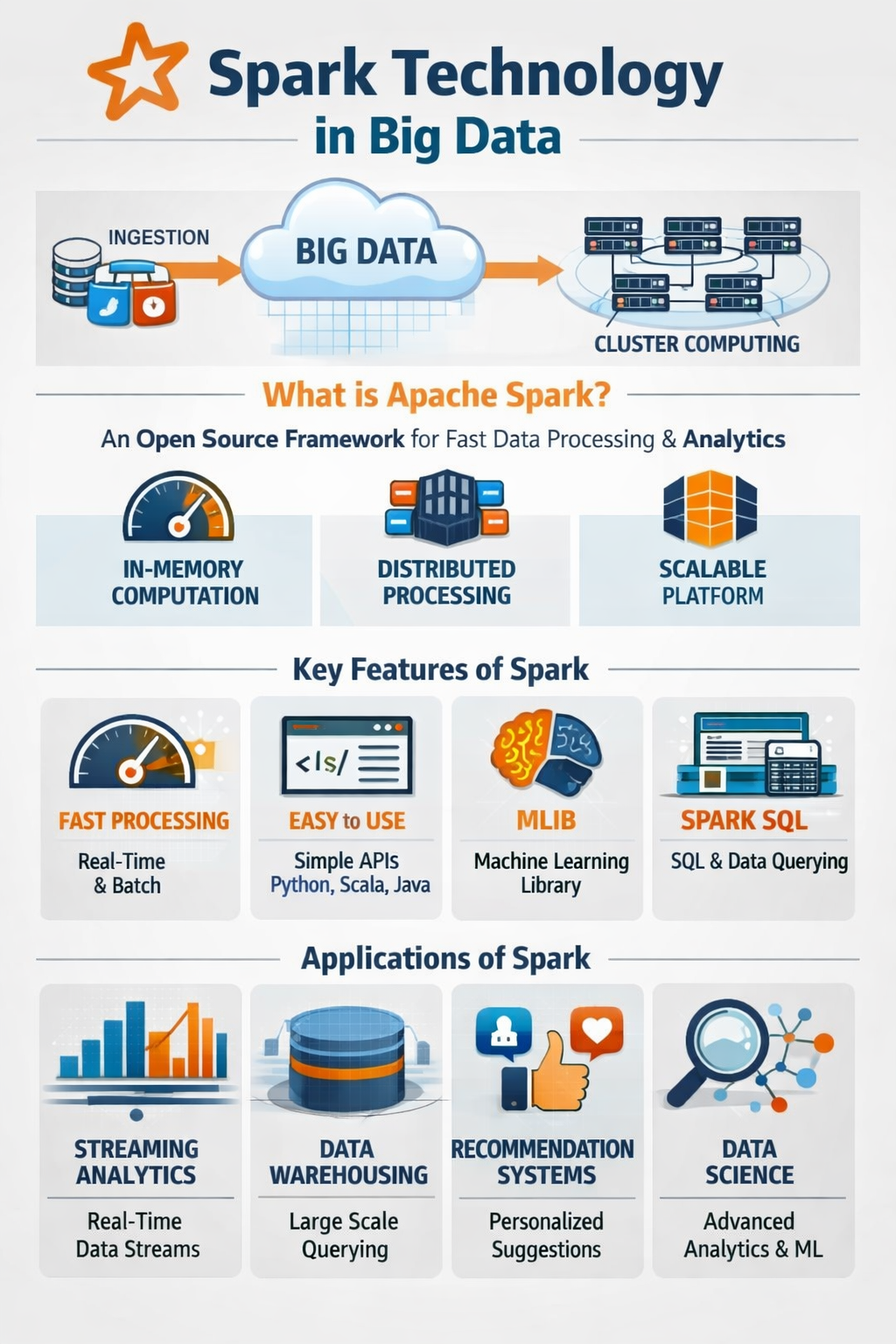
Apache Spark is an open-source, distributed data processing engine designed to handle massive datasets with incredible speed.
If big data is a mountain of raw materials, Spark is the high-speed factory that processes it into finished goods. It is currently the industry standard for big data analytics, machine learning, and real-time data processing.
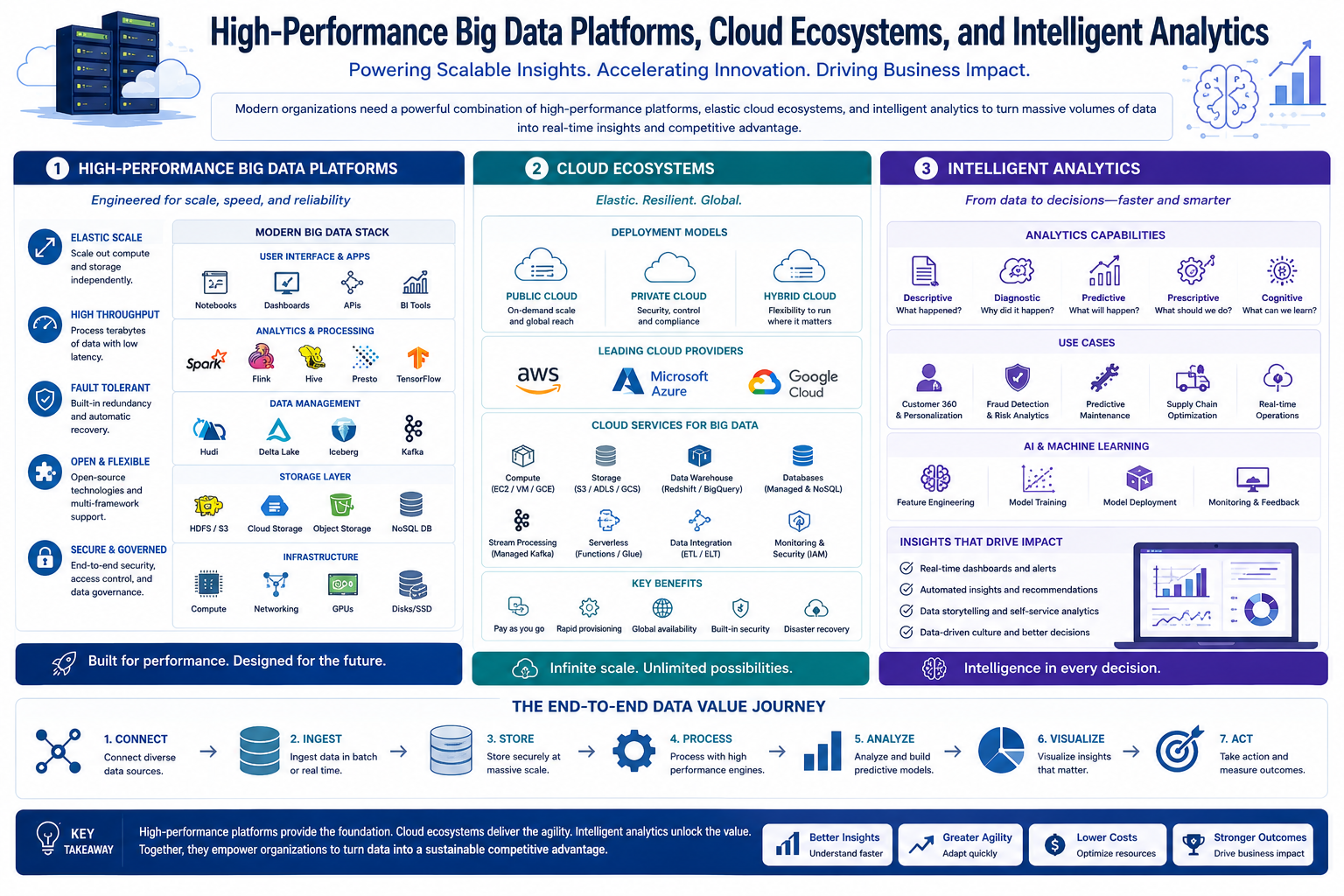
The provided text offers a comprehensive technical summary of Apache Spark, an open-source framework designed for high-speed distributed computing. It highlights how the platform utilizes in-memory processing and parallel execution to overcome the performance limitations found in traditional disk-based systems.
Apache Spark is a robust open-source framework engineered to facilitate large-scale data processing through a distributed computing model. By utilizing in-memory computation, the system achieves significantly faster speeds than traditional disk-based methods, making it ideal for real-time analytics and complex machine learning tasks. The platform’s architecture relies on a driver program and executor nodes to manage tasks across vast clusters, ensuring both scalability and fault tolerance. Its diverse ecosystem includes specialized components for SQL queries, stream processing, and graph analysis, supporting multiple programming languages like Python and Scala.

Cloud-Based Big Data Management Technology is the practice of storing, cleaning, organizing, and analyzing massive datasets using remote servers hosted on the internet, rather than using physical, on-premise servers located inside a company's own data center.
The provided video outlines five distinct paradigms of computational architecture, detailing how each handles data processing and storage. Cloud computing serves as a centralized hub for scalable, remote resources, while edge and fog computing decentralize this power by moving tasks closer to the data source to minimize delay. In contrast, High-Performance Computing (HPC) utilizes massive clusters of traditional hardware to solve labor-intensive mathematical problems through brute-force parallel processing. The most radical shift is quantum computing, which leverages the unique principles of subatomic physics to perform calculations that are impossible for standard computers.
Here we explore the essential role of Big Data Visualization in converting overwhelming, high-speed datasets into actionable graphical formats. It emphasizes that traditional charting methods must be replaced by advanced techniques like heatmaps, treemaps, and data binning to prevent visual clutter and system crashes. The source highlights the importance of interactive design, allowing users to start with a broad summary before drilling down into specific details.
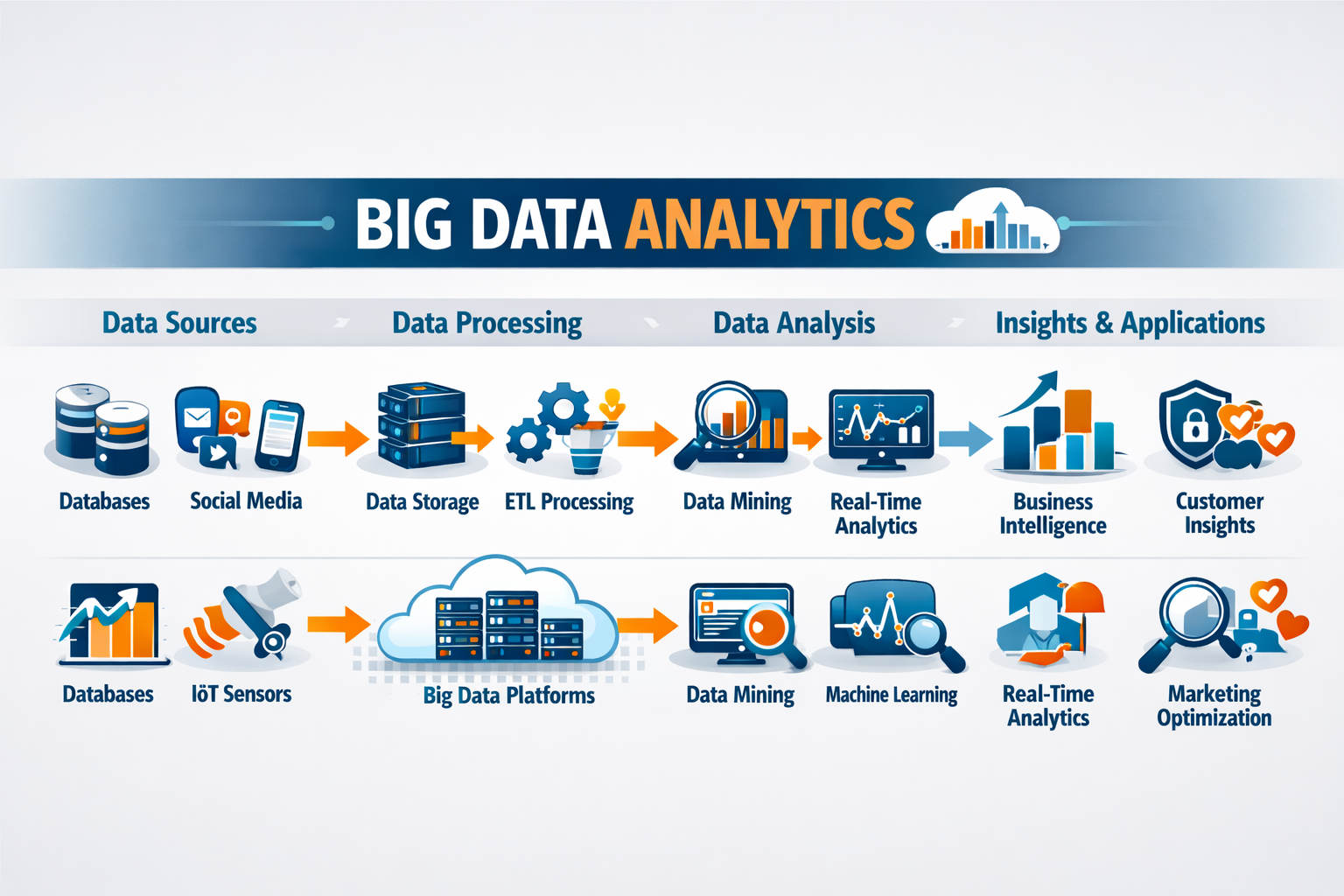
Big Data Analytics is the complex process of examining massive, fast-moving, and varied datasets to uncover hidden patterns, correlations, market trends, and customer preferences.
Essentially, it is the science of turning raw, overwhelming "noise" into actionable intelligence that organizations can use to make better, faster business decisions.
This video provides a comprehensive overview of Big Data Analytics, detailing how organizations transform massive volumes of complex information into actionable intelligence.
