Text size
Line height
Text spacing
 |
This micro-credential provides a comprehensive, intermediate-level foundation in big data. It progresses from core conceptual definitions and applications to hands-on infrastructure management (Hadoop & NoSQL). Students then advance to batch processing techniques (via MapReduce programming) and wrap up with live data streams and real-time technology using Apache Storm. |
Big Data is defined by its massive Volume, high Velocity, and diverse Variety, representing an ocean of information that traditional software simply cannot handle. To make sense of this chaos, Big Data Computing utilizes distributed frameworks like Hadoop and Apache Spark, which break tasks into smaller chunks and process them across clusters of servers simultaneously. This computational power transforms raw data into Applications that define modern life, from Healthcare systems that predict disease outbreaks to Retail algorithms that personalize shopping experiences and Finance tools that detect fraud in real-time. Ultimately, Big Data is the engine of the 21st century, turning digital noise into the actionable insights that power smart cities and global economies.
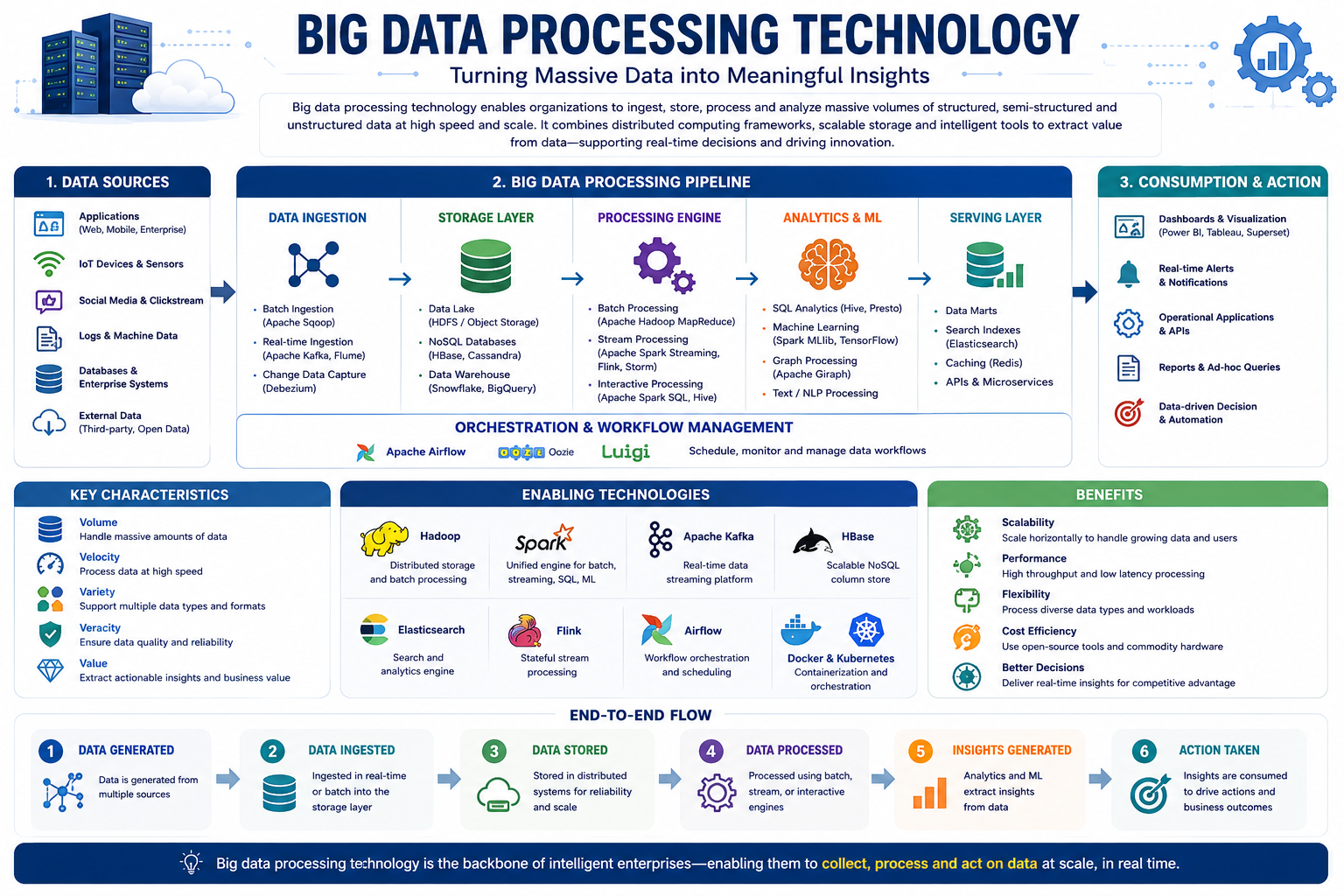
The infographics describe in detail the foundation layers of big data. Also, it shows the key enablers and tools associated with big data.
The slides describe the core components and processes involved in big data management and modelling. It outlines the Hadoop architecture, highlighting how systems like HDFS and YARN handle distributed storage and resource scheduling. The visual further breaks down data processing services that utilize programming frameworks such as MapReduce, Apache Spark, and Flink for high-speed analysis. Additionally, it compares query-based processing tools like Hive and Presto, which facilitate efficient data retrieval through SQL-like languages.
The slides outline the five essential stages required for efficient big data processing, beginning with the extraction and validation of information from various sources. It details how data is transformed into usable formats and loaded into centralized systems before being analyzed through visualization and business intelligence tools. The final phase emphasizes the role of machine learning, explaining how supervised, unsupervised, and reinforcement learning help automate pattern recognition and predictive modeling.
The provided video explores the essential structure and logic behind the MapReduce architectural model. It outlines the fundamental principles that govern how the system processes large-scale data across distributed networks. By examining the individual components that make up the framework, the text illustrates how hardware and software work in tandem. Additionally, the source addresses the programming methodologies required to implement and manage these complex data tasks. Overall, the documentation serves as a comprehensive guide to understanding the internal mechanics of this data processing technology.
The provided text outlines the core structural and operational elements of the MapReduce architecture. It highlights the fundamental conceptual theories that underpin this specific data processing model. Additionally, the source identifies the physical components required to build and maintain the system's infrastructure. It also addresses the software development side by focusing on the specialized programming techniques used within the framework.
The slides is continuing the first part slides. Overall, these excerpts serve as a foundational guide for understanding how the technology organizes and executes large-scale tasks. Through these three focus areas, the material offers a comprehensive look at the mechanics of distributed computing.
 |
Real-time data processing in big data refers to the continuous ingestion, analysis, and streaming of data as it is generated. Unlike traditional batch processing, which collects and processes large volumes of data at scheduled intervals, real-time processing operates on data almost instantly often within milliseconds or seconds. |
The slides explore the fundamental principles and practical applications of real-time big data processing, a method that prioritizes instantaneous data analysis over traditional delayed batching. By utilizing advanced frameworks like the Lambda or Kappa architectures, organizations can ingest and evaluate continuous information streams to achieve operational agility.
This text explores the fundamental principles and technical frameworks behind real-time data processing, focusing on systems that analyze information instantly as it is generated. It highlights the transition from traditional batch processing to continuous data streaming, emphasizing the need for low latency and scalability in modern digital environments.
