6. Chapter 6: Coordination and Agreement
6.1. Introduction
Introduction
Failure assumptions and failure detector- Assumptions:
- Each pair of processes is connected by reliable channels.
- No process failure implies a threat to the other processes’ ability to communicate.
- In any particular interval of time, communication between some processes may succeed while communication between others is delayed.
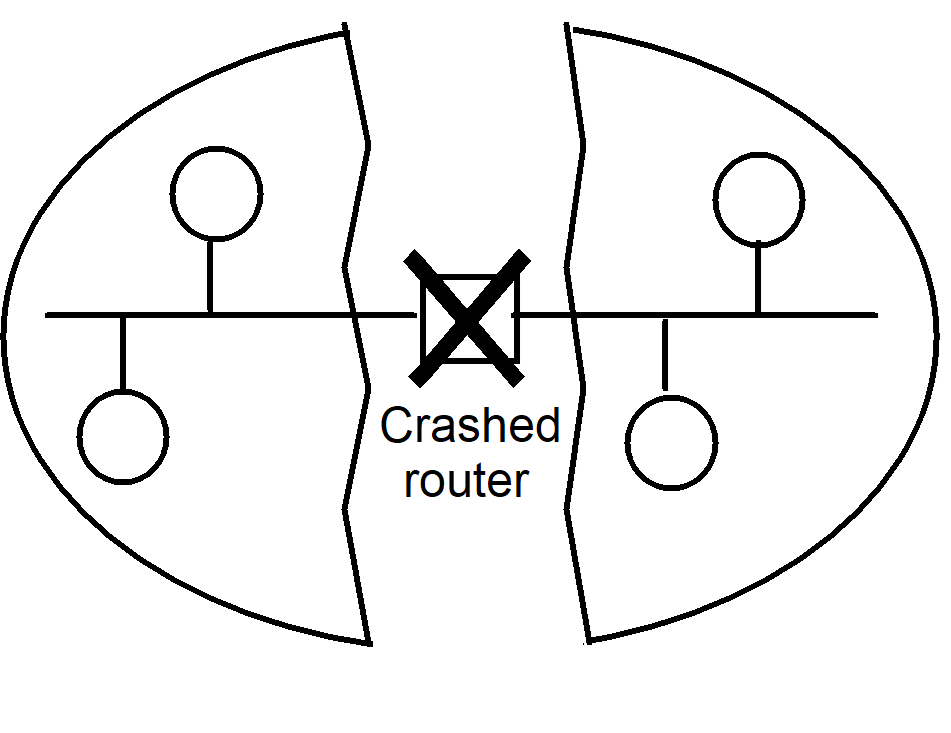
- Example: failure of a router between two networks -> network partition
- Failure detector
- Service that processes queries about whether a particular process has failed.
- (a) Unreliable failure detectors
- Produce one of two values: Unsuspected or Suspected
- May or may not accurately reflect whether the process has actually failed.
- Unsuspected -> the detector has recently received evidence suggesting that the process has not failed
- Suspected -> the failure detector has some indication that the process may have failed
- (b) Reliable failure detector
- Always accurate in detecting a process’s failure
- Unsuspected or Failed
- Failed -> the detector has determined that the process has crashed.
- Algorithm for unreliable failure detector
- Each process p sends a ‘p is here’ message to every other process.
- It does this every T seconds.
- Maximum message transmission time: D seconds
- If the local failure detector at process q does not receive a ‘p is here’ message within T + D seconds of the last one, then it reports to q that p is Suspected.
- If it subsequently receives a ‘p is here’ message, then it reports to q that p is OK.
- In a synchronous system, the failure detector can be made into a reliable one.
- D is not an estimate but an absolute bound on message transmission times; the absence of a ‘p is here’ message within T + D seconds indicates that p has crashed.