SKR 5302: Advanced Distributed Computing
8. Chapter 8: Replication
8.2. Fault-tolerant services
Introduction:
- Each replica manager is assumed to behave according to a specification of the semantics of the objects it manages, when they have not crashed.
- Anomalies can arise when there are several replica managers.
- Example:
- Replication system, where a pair of replica managers at computers A and B each maintain replicas of two bank accounts, x and y.
- Clients read and update the accounts at their local replica manager but try another replica manager if the local one fails.
- Replica managers propagate updates to one another in the background after responding to the clients.
- Both accounts initially have a balance of $0.
- Client 1 updates the balance of x at its local replica manager B to be $1 and then attempts to update y’s balance to be $2, but discovers that B has failed.
- Client 1 therefore applies the update at A instead.
- Now client 2 reads the balances at its local replica manager A.
- It finds first that y has $2 and then that x has $0 – the update to bank account x from B has not arrived, since B failed.
- Client 2 should have read a balance of $1 for x, given that it read the balance of $2 for y, since y’s balance was update after that of x.
Client 1: Client 2:
setBalanceB(x, 1)
setBalanceA(y, 2)
getBalanceA(x)
-> 0
- There are various correctness criteria for replicated objects.
- A replicated shared object service is said to be linearizable if for any execution there is some interleaving of the series of operations issued by all the clients that satisfies the following two criteria:
- The interleaved sequence of operations meets the specification of a (single) correct copy of the objects.
- The order of operations in the interleaving is consistent with the real times at which the operations occurred in the actual execution.
- The real-time requirement in linearizability captures our notion that clients should receive up-to-date information.
- But, the presence of real time raises the issue of linearizability’s practically – we cannot synchronize clocks to the required degree of accuracy.
ii. Sequential consistency
- It just captures an essential requirement concerning the order in which requests are processed without appealing to real time.
- Criteria:
- The interleaved sequence of operations meets the specification of a (single) correct copy of the objects.
- The order of operations in the interleaving is consistent with the program order in which each individual client executed them.
- The interleaving of operations can shuffle the sequence of operations from a set of clients in any order, as long as each client’s order is not violated and the result of each operation is consistent, in terms of objects’ specification, with the operations preceded it.
- This is similar to shuffling together several packs of cards so that they are intermingled in such a way as to preserve the original order of each pack.
- Every linearizable service is also sequentially consistent, since real-time order reflects each client’s program order.
- But the converse does not hold.
- Example:
- The real-time criteria for linearizablity is not satisfied, since getBalanceA(x) -> 0 occurs later than setBalanceB(x, 1); but the following interleaving satisfies both criteria for sequential consistency: getBalanceA(y) -> 0, getBalanceA(x) -> 0, setBalanceB(x, 1), setBalanceA(y, 2).
Client A: Client 2:
setBalanceB(x, 1)
getBalanceA(y) -> 0
getBalanceA(x) -> 0
setBalanceA(y, 2)
iii. Passive (primary-backup) replication
- There is at any one time a single primary replica manager and one or more secondary replica managers – ‘backups’ or ‘slaves’.
- Front ends communicate only with the primary replica manager to obtain the service.
- The primary replica manager executes the operations and sends copies of the updated data to the backups.
- If the primary fails, one of the backups is promoted to act as the primary.
- Sequence of events when a client requests an operation to be performed:
- Request: The front end issues the request, containing a unique identifier, to the primary replica manager.
- Coordination: The primary takes each request atomically, in the order in which it receives it. It checks the unique identifier, in case it has already executed the request, and if so it simply resends the response.
- Execution: The primary executes the request and stores the response.
- Agreement: If the request is an update, then the primary sends the updated state, the response and the unique identifier to all the backups. The backups send an acknowledgement.
- Response: The primary responds to the front end, which hands the response back to the client.
- The system implements linearizability if the primary is correct, since the primary sequences all the operations upon the shared objects.
- If the primary fails, then the system retains linearizability if a single backup becomes the new primary, and if
- The primary is replaced by a unique backup (if two clients begin using two backups, then the system could perform incorrectly)
- The replica managers that survive agree on which operations had been performed at the point when the replacement primary takes over.
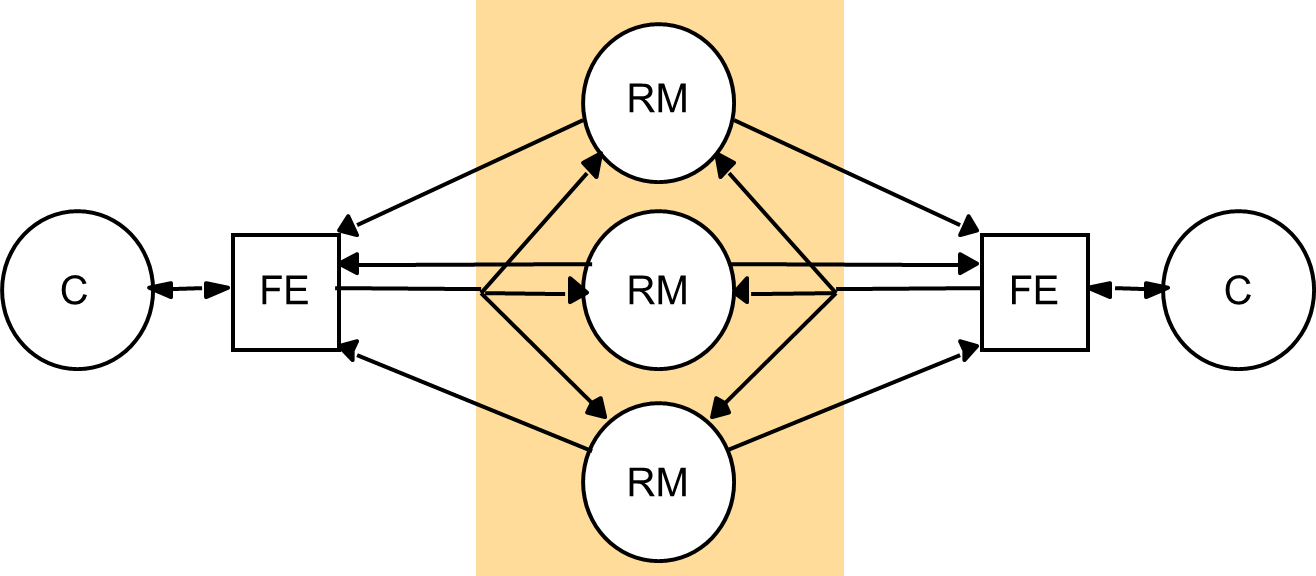
iv. Active replication
- The replica managers are state machines that play equivalent roles and are organized as a group.
- Front ends multicast their requests to the group of replica managers and all the replica managers process the request independently but identically and reply.
- If any replica manager crashes, this need have no impact upon the performance of the service, since the remaining replica managers continue to respond in the normal way.
- The sequence of events when a client requests an operation to be performed:
- Request:
- The front end attaches a unique identifier to the request and multicasts it to the group of replica managers, using a totally ordered, reliable multicast primitive.
- The front end is assumed to fail by crashing at worst.
- It does not issue the next request until it has received a response.
- Coordination: The group communication system delivers the request to every correct replica manager in the same (total) order.
- Execution:
- Every replica manager executes the request.
- Since they are state machine and since requests are delivered in the same total order, correct replica managers all process the request identically.
- The response contains the client’s unique request identifier.
- Agreement: No agreement phase is needed
- Response:
- Each replica manager sends its response to the front end.
- The front end might passes the first response to arrive back to the client and discards the rest.
- The system achieves sequential consistency.
- Each front end’s requests are served in FIFO order, which is the same as ‘program order’.
- It is not linearizability → The total order in which the replica managers process request is not necessarily the same as the real-time order in which the clients made their requests
Figure 4: Active replication